前面写了将 Faster R-CNN 用在自己的数据集上,这次来写一下 RCNN 的环境搭建和训练过程。
深坑,请注意。
为什么说是坑呢?
首先,它是 Matlab 的……没有歧视 Matlab 的意思,只是前面都是在 py,突然换成 Matlab 很不适应。
其次,里面使用的 Caffe 是一个非常早的 v0.999 版本。里面的各种用法都和现在版本的不一样!
再次……遇到问题,搜出来的都是 py-faster-rcnn 的处理办法……
虽然官方 README 里面写得比较清楚了,但还是遇到不少麻烦。
好吧,不吐槽,开工。
源代码的获取
这个不多说,git clone https://github.com/rbgirshick/rcnn 就好了。
然后,下载 Caffe v0.999,放到 $RCNN_ROOT/external 里面,改名为 caffe 。
编译 Caffe
首先,修改一些代码:
找到 Makefile 文件,大约 266 行左右关于 Matlab 的说明段,整体替换成如下代码(必须使用 Tab 缩进):
$(MAT$(PROJECT)_SO): $(MAT$(PROJECT)_SRC) $(STATIC_NAME)
@ if [ -z "$(MATLAB_DIR)" ]; then \
echo "MATLAB_DIR must be specified in $(CONFIG_FILE)" \
"to build mat$(PROJECT)."; \
exit 1; \
fi
$(MATLAB_DIR)/bin/mex $(MAT$(PROJECT)_SRC) \
CXXFLAGS="\$CXXFLAGS $(CXXFLAGS) $(WARNINGS)" \
CXXLIBS="\$CXXLIBS $(STATIC_NAME) $(LDFLAGS)" -output $@
@ echo
这样就能解决 “错误使用 -o 参数” 和其他关于链接的问题。
然后,找到 $CAFFE_ROOT/include/caffe/util/math_functions.hpp,将
using std::signbit;
DEFINE_CAFFE_CPU_UNARY_FUNC(sgnbit, y[i] = signbit(x[i]));
改为
// using std::signbit;
DEFINE_CAFFE_CPU_UNARY_FUNC(sgnbit, y[i] = std::signbit(x[i]));
这样能解决一个很奇怪的编译问题。
如果你的 GPU 比较老(capability<3),那么即使顺利通过编译,运行的时候也会直接报错的。修改方法如下:
找到 $CAFFE_ROOT/include/caffe/common.hpp,在第 162 行左右找到 CAFFE_GET_BLOCKS 函数,改成
// CUDA: number of blocks for threads.
inline int CAFFE_GET_BLOCKS(const int N) {
int blocks = (N + CAFFE_CUDA_NUM_THREADS - 1) / CAFFE_CUDA_NUM_THREADS;
return std::min(blocks,65535);
}
最后,按照这个文章里的记录进行配置和编译。我们需要编译 all 、 test 、 pycaffe 、 matcaffe 。
如果你的 GPU 比较新,可以把 CUDA_ARCH(我也不知道这个东西是干啥的)设置稍微高一点。例如,在 GTX1060 上,我用的是
CUDA_ARCH := -gencode arch=compute_20,code=sm_20 \
-gencode arch=compute_20,code=sm_21 \
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_52,code=sm_52 \
-gencode arch=compute_60,code=sm_60 \
-gencode arch=compute_61,code=sm_61 \
-gencode arch=compute_61,code=compute_61
不报错。在 GTX540 上,只能用到 52 。
当然,跑 test 是有一定概率出错的,并且 100% 通不过全部测试。忽略吧……
第一仗 编译 结束。
Matlab 准备
这个,照着 README 来就好了。
从 $RCNN_ROOT 里面启动 matlab,会出现 R-CNN startup done 。如果没有,那么手动运行一下 >> startup 。
然后是自动下载和编译依赖库,只需要我们 >> rcnn_build() 一下就好了。一般不会出问题。
最后进行一个小测试: >> key = caffe('get_init_key'),如果结果是 -2,恭喜。
第二仗 Matlab,轻松结束。
跑 Demo
这个也要按照 README 来。
进入 $RCNN_ROOT
执行./data/fetch_models.sh 获取训练好的 Model 。如遇到网络问题,请挂梯子。
执行./data/fetch_selective_search_data.sh 获取在 ImageNet 上使用 SelectiveSearch 提取出来的 Window 信息(这个不知道是干啥的)。如遇到网络问题,请挂梯子。
启动 Matlab,执行 rcnn_demo
第三仗 Demo ,轻松结束。
Fine Tune 自己的数据
简直了!
准备数据
可以按照将 Faster R-CNN 用在自己的数据集上来准备数据。也就是说,用 PascalVOC 的壳,里面装的是自己的数据。
RCNN 需要依赖 VOCdevkit 里面的一些文件的。我们也需要对这些文件进行一些修改。找到 VOCdevkit/VOCcode/VOCinit.m,将里面的类别标签替换成你自己的。同时,如果你的图片是 PNG 格式的,需要在这个文件中查找 jpg,替换成 png 。
由于这篇文章中使用的是 Python,比较灵活,做 Annotation 的时候一些细节没有考虑到,导致后面会出错。如果你在后面的训练过程中发现 “网络加载完毕就崩溃”,那么可以看看这里:
VodDevkit 里面会将 xml 转为 Matlab Struct,而转换用的代码是非常……额……原始……的。 XML 稍有问题,就会死给你看。比较容易出错的地方有:
- XML 文件头部,不能有
<?xml version="1.0" ?>记号 - 使用 LabelImage 标注的话,不能有
verified="no"或者verified="yes"记号 - 图片中没有物体,会报错
- 必须设置
folder为VOC2007 - 有多余空格会报错
所以,我们需要做两个修改:
VOCdevkit/VOCcode/VOCxml2struct.m中,将xml(xml==9|xml==10|xml==13)=[];改为xml(xml==9|xml==10|xml==13|xml==' ')=[];VOCdevkit/VOCcode/VOCreadxml.m中,改为下面的代码
function rec = VOCreadxml(path)
if length(path)>5&&strcmp(path(1:5),'http:')
xml=urlread(path)';
else
f=fopen(path,'r');
xml=fread(f,'*char')';
fclose(f);
xml = strrep(xml,'<?xml version="1.0" ?>','');
xml = strrep(xml,'fooImages','VOC2007');
xml = strrep(xml,' verified="no"','');
xml = strrep(xml,' verified="yes"','');
end
rec=VOCxml2struct(xml);
或者,我们可以借鉴一下 LabelImage 的代码,将 Annotation 再进行一次转换。由于长度原因,代码我放 gist 上面了,有两个文件,分别是 pascal_voc_io.py 和 voc_annotation_correct.py 。经过转换后,我们的 RCNN 就会听话许多。
进行训练
训练分为四步: 计算候选区域、 CNN 的 Fine-Tune 、提取特征、训练 SVM
计算候选区域
如果已经运行过 R-CNN 的 demo,那就一定执行过
rcnn/data下的fetch_selective_search_data.sh脚本,在selective_selective_data文件夹下就一定有一系列的.mat文件,这就是作者预先计算好的候选区域信息(实际上是候选区域的坐标)。如果不自行计算候选区域,下一步提取特征的时候就会使用 voc_2007_*.mat 中储存的候选区域信息,会使结果出错。
所以,应对方法是…… 删除!
cd ./data/selective_search_data
rm voc_2007_train.mat
rm voc_2007_val.mat
rm voc_2007_trainval.mat
rm voc_2007_test.mat
然后我们还需要再根据自己的数据集来计算这些文件。这里对这篇博客中的代码进行了一些修改:
function selective_search_boxes_generator(chunk)
mat_file = sprintf('./data/selective_search_data/voc_2007_%s.mat', chunk);
if exist(mat_file, 'file')
fprintf('File exists\n');
return
end
% image_ids = load(sprintf('./datasets/VOCdevkit2007/VOC2007/ImageSets/Main/%s.txt', chunk));
image_ids = textread(sprintf('./datasets/VOCdevkit2007/VOC2007/ImageSets/Main/%s.txt', chunk),'%s');
image_num = size(image_ids, 1);
images = cell(1, image_num);
boxes = cell(1, image_num);
fprintf('Computing candidate regions...\n');
th = tic();
fast_mode = true;
im_width = 500;
parfor i = 1 : image_num
image_id = cell2mat(image_ids(i));
images{1, i} = image_id;
image_file = sprintf('./datasets/VOCdevkit2007/VOC2007/JPEGImages/%s.png', image_id);
im = imread(image_file);
box = selective_search_boxes(im, fast_mode, im_width);
% Rounding is necessary, or 'loss' will always be '0' when fine-tuning.
boxes{1, i} = round(box);
fprintf('%d / %d %s.png\n', i,image_num,image_id);
end
fprintf('Finished, costs %.3fs\n', toc(th));
fprintf('Saving MAT file to %s...\n', mat_file);
save(mat_file, 'images', 'boxes');
fprintf('Done\n');
将上述文件保存成 selective_search_boxes_generator.m,然后启动 Matlab,执行
selective_search_boxes_generator('train');
selective_search_boxes_generator('val');
selective_search_boxes_generator('trainval');
selective_search_boxes_generator('test');
下面是照着官方教程来的:
继续在 Matlab 里面执行
imdb_trainval = imdb_from_voc('datasets/VOCdevkit2007', 'trainval', '2007');
imdb_test = imdb_from_voc('datasets/VOCdevkit2007', 'test', '2007');
rcnn_make_window_file(imdb_trainval, 'external/caffe/examples/pascal-finetuning');
rcnn_make_window_file(imdb_test, 'external/caffe/examples/pascal-finetuning');
以获取 “Window File” 。执行完成后,建议去 $CAFFE_ROOT/examples/pascal-finetuning/ 里面看看 window_file_voc_2007_test.txt 和 window_file_voc_2007_trainval.txt 两个文件。
这两个文件的格式是这样的:
# image_index
img_path
channels
height
width
num_windows
class_index overlap x1 y1 x2 y2
其中如果 class_index 是 0 的话,说明这个框框是背景类。如果 class_index 全部都是 0,请照着上面的说明转一下标注文件。
修改网络配置
pascal_finetune_solver.prototxt- 调整迭代次数
max_iter(作者说在 Pascal VOC 2012 上训练,4w iter 就收敛了) - 调整每次测试数量
test_iter(别太大) - 调整测试频率
test_interval(别太频繁) - 调整快照频率
snapshot(别太频繁)
- 调整迭代次数
pascal_finetune_train.prototxt- 305 行左右的
num_output:改成你的类别数+1 - 如果报显存不足的话,调整
batch_size
- 305 行左右的
pascal_finetune_val.prototxt- 305 行左右的
num_output:改成你的类别数+1 - 如果报显存不足的话,调整
batch_size
- 305 行左右的
最理想状态是 max_iter/test_interval*test_iter=你的测试图片总数。
好像不用修改层的名字。
训练特征提取网络
进入 $CAFFE_ROOT/examples/pascal-finetuning
GLOG_logtostderr=1 ../../build/tools/finetune_net.bin pascal_finetune_solver.prototxt < 到 rcnn 文件夹的路径>/rcnn/data/caffe_nets/ilsvrc_2012_train_iter_310k 2>&1 | tee log.txt
训练完毕后,在当前文件夹下会生成一大堆 pascal_finetune_train_iter_XXXX 和 pascal_finetune_train_iter_XXXX.solverstate 文件,这就是我们的快照。数值最大的那个就是我们的最终模型。
选择一个不带.solverstate 的文件,改名为 finetune_voc_2007_trainval_iter_70k,复制到 $RCNN_ROOT/data/caffe_nets 下备用。
回顾训练过程
这个版本的 Caffe 提供了一些 Log 可视化工具,位于 $CAFFE_ROOT/tools/extra 。使用前需要将这里面的.py 、.sh 、.example 文件加上运行位(chmod +x)。
将 $CAFFE_ROOT/examples/pascal-finetuning/log.txt 复制到 $CAFFE_ROOT/tools/extra 里面。执行./parse_log.sh log.txt,然后执行
./plot_training_log.py.example < 曲线类型参数> < 图片文件名>.png log.txt
其中曲线类型可以为(请把前面的序号-1……我偷懒不想打表格)
- Test accuracy vs. Iters
- Test accuracy vs. Seconds
- Test loss vs. Iters
- Test loss vs. Seconds
- Train learning rate vs. Iters
- Train learning rate vs. Seconds
- Train loss vs. Iters
- Train loss vs. Seconds
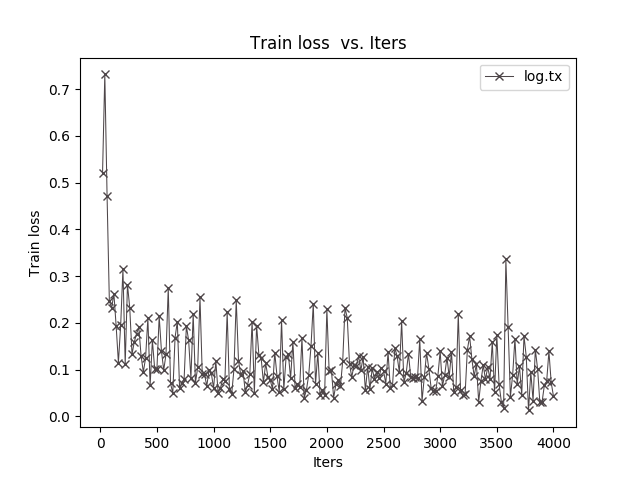
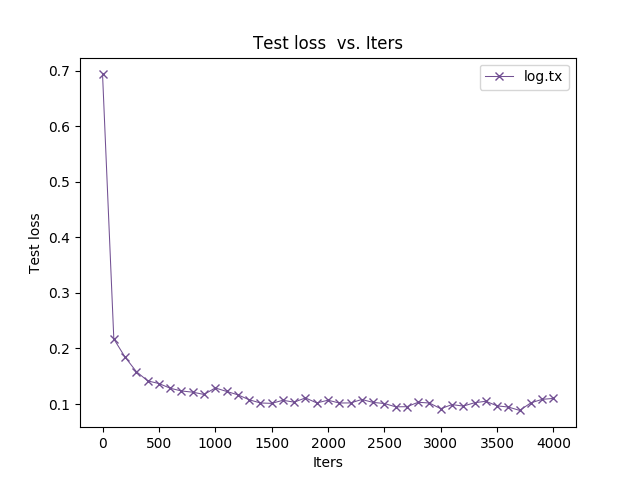
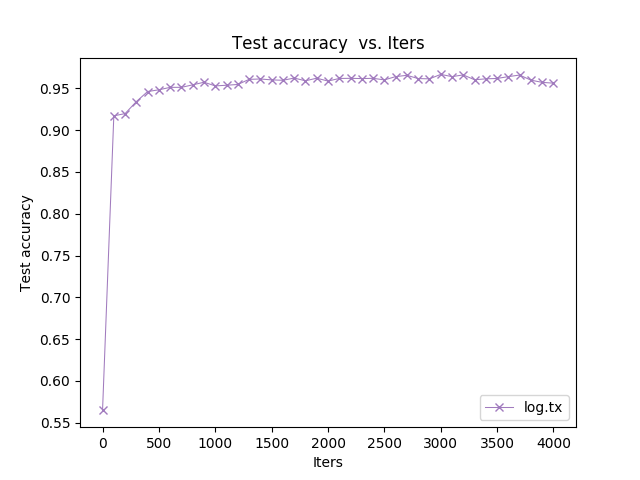
想问这里的 Test Accuracy 是什么鬼?为什么这么高?
进行特征提取
回到 $RCNN_ROOT,进入 Matlab,执行
rcnn_exp_cache_features('train');
rcnn_exp_cache_features('val');
rcnn_exp_cache_features('test_1');
rcnn_exp_cache_features('test_2');
程序分别将 train 、 val 、 test 前半部分和后半部分的图片送入网络,提取 pool5 层的输出作为特征,最后保存到硬盘上。生成文件非常多,速度非常满。不仅会用到 GPU,而且由于代码中使用了 parfor,CPU 大多也是慢负荷运转的。
速度有多慢呢?
rcnn: cache features: 213/900
[features: 6.928s]
[saving: 2.215s]
[avg time: 9.793s (total: 2076.135s)]
这里遇到了一个坑: 我们的数据集中,不能保证每张图片上面都有目标物体……好像是会导致 bbox 坐标出现 NaN NaN NaN NaN 的奇葩状况。为了解决这个问题,我对 $RCNN_ROOT/rcnn_extract_regions.m 做了一点小修改,在此函数的最前面加入了一句 boxes(isnan(boxes))=0; 。这样做能解决掉上述问题,但是不知道对后续流程有没有什么影响。
训练 SVM
最后还要再使用 liblinear 训练一个分类器嘛……
test_results = rcnn_exp_train_and_test()
一句话就能解决了。如果 liblinear 出错,请删除 $RCNN_ROOT/liblinear_train.mexa64,到 $RCNN_ROOT 里面打开 Matlab,运行 >> rcnn_build() 重新编译一下 liblinear 即可。
在测试结束时,程序绘制出 precision/recall 曲线和 ap 。 precision/recall 曲线保存在 $RCNN_ROOT/cachedir/voc_2007_test/face_pr_voc_2007_test.jpg,以方便没有界面的苦逼孩子观看。同时,训练好的模型被保存在了 $RCNN_ROOT/cachedir/voc_2007_trainval/rcnn_demo.m 里。
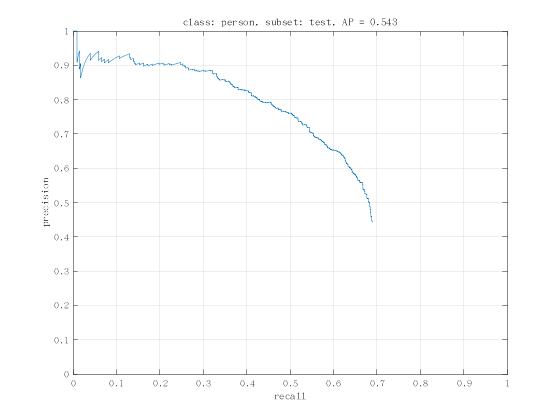
好像……好像结果不怎么好的样子……
还有,我知道什么是 Recall,什么是 Accuracy,但是这里的 Recall-Accuracy 曲线就不明白了。
后续
由于整个过程太长了,所以写了个自动脚本。在这里。如有需要,请修改后使用。比如,第一步删文件要不要那么狠,第三步替换一下你的迭代次数。
总结
第一次感受到快被坑哭了是什么感觉。莫名其妙地各种报错,报各种莫名其妙的错,最后 AP 也是超级低。
环境折腾小一周,训练折腾小一周……十分感谢这个博主,这是我能找到的最全面的一个 RCNN 使用笔记了,使我少跳了许多坑。