历经一个多月,也钻了很多牛角尖,终于成功一次,把过程 Log 贴出来备忘。
如果这篇文章对你有帮助,或者有任何什么问题,都欢迎在下面留言。
获取并修改代码
首先,我们需要获取源代码:
git clone --recursive https://github.com/rbgirshick/py-faster-rcnn.git
之后是对代码的各种修改:
Caffe 版本升级(可选)
大神是自己将 Caffe fork 了一份,然后进行魔改,之后就弃坑了。最新的 Caffe 支持 Cuda8.0 等各种加成,但是这里面的版本就不支持。 如果你喜欢折腾的话,可以将自带的 Caffe 进行一下升级:
cd caffe-fast-rcnn
git remote add caffe https://github.com/BVLC/caffe.git
git fetch caffe
git merge -X caffe/master
这里请注意一下,在 2017 年 1 月 10 日之前,官方 Caffe 版本还是 RC3,直接 merge 就可以了;但是在 2017 年 2 月 5 日之后,直接 merge 会出错。哪位大神如果有了新的 Merge 方法,或者消除冲突的办法,可以在下面回复,感激不尽。
更新: 可以合并 RC5 这个 Tag,然后只保留远端版本。
错误修正
遇到冲突的文件,我只保留了远程更改。
找到 $FRCN_ROOT/caffe-fast-rcnn/include/caffe/layers/python_layer.hpp,将里面的 self_.attr("phase") = static_cast<int>(this->phase_); 注释掉。
找到 $FRCN_ROOT/lib/roi_data_layer/minibatch.py,将 173 行左右的 cls = clss[ind] 改为 cls = int(clss[ind])。
消除一个编译错误
找到下面两个文件
$FRCN_ROOT/caffe-fast-rcnn/src/caffe/test/test_smooth_L1_loss_layer.cpp
$FRCN_ROOT/caffe-fast-rcnn/src/caffe/test/test_roi_pooling_layer.cpp
去掉最前面的
typedef ::testing::Types<GPUDevice<float>, GPUDevice<double> > TestDtypesGPU;
并将文件里面的 TestDtypesGPU 改为 TestDtypesAndDevices
另外,在 $FRCN_ROOT/caffe-fast-rcnn/src/caffe/test/test_smooth_L1_loss_layer.cpp 中,我们还需要去掉下面这行代码才能通过编译:
#include "caffe/vision_layers.hpp"
消除一个路径错误
$FRCN_ROOT/lib/setup.py 中需要使用 GPU 来编译一个叫做「nms」的东西(非极大值抑制)。
在这个文件的 locate_cuda 函数中,我们可能需要手动指定一下 cuda 的路径。
修正几个 Typo
- 在
$FRCN_ROOT/lib/fast_rcnn/train.py中添加import google.protobuf.text_format $FRCN_ROOT/lib/roi_data_layer/minibatch.py里面的约 25 行:fg_rois_per_image = np.round(cfg.TRAIN.FG_FRACTION * rois_per_image).astype(np.int)$FRCN_ROOT/lib/datasets/ds_utils.py里面的约 12 行:hashes = np.round(boxes * scale).dot(v).astype(np.int)$FRCN_ROOT/lib/fast_rcnn/test.py里面的约 129 行:hashes = np.round(blobs['rois'] * cfg.DEDUP_BOXES).dot(v).astype(np.int)$FRCN_ROOT/lib/rpn/proposal_target_layer.py里面:- 约 60 行:
fg_rois_per_image = np.round(cfg.TRAIN.FG_FRACTION * rois_per_image).astype(np.int) - 约 124 行:
cls = int(clss[ind]) - 约 166 行:
size=int(fg_rois_per_this_image) - 约 177 行:
size=int(bg_rois_per_this_image) - 约 184 行:
labels[int(fg_rois_per_this_image):] = 0
- 约 60 行:
添加 CPU 支持
因为网络比较大,rbg 大神压根没想让你用 cpu 来跑。不过为了完整一点,我们还是加上 CPU 的支持吧。
在源代码的 pull-request 里面可以找到几个 cpu 的实现。经过测试,这个版本 的代码可以拿来直接使用。其他几个版本,例如 这个版本,就需要把 base_lr 设置得非常非常低,特被难以训练。
如果希望使用纯 CPU
这是个奇怪的需求…… 对…… 而且特别麻烦。也就是说,我们得剔除一些 GPU 的代码。 在 $FRCN_ROOT/lib/setup.py 中,注释掉
CUDA = locate_cuda()
self.set_executable('compiler_so', CUDA['nvcc'])
Extension('nms.gpu_nms',
['nms/nms_kernel.cu', 'nms/gpu_nms.pyx'],
library_dirs=[CUDA['lib64']],
libraries=['cudart'],
language='c++',
runtime_library_dirs=[CUDA['lib64']],
# this syntax is specific to this build system
# we're only going to use certain compiler args with nvcc and not with
# gcc the implementation of this trick is in customize_compiler() below
extra_compile_args={'gcc': ["-Wno-unused-function"],
'nvcc': ['-arch=sm_35',
'--ptxas-options=-v',
'-c',
'--compiler-options',
"'-fPIC'"]},
include_dirs = [numpy_include, CUDA['include']]
),
在 $FRCN_ROOT/lib/fast_rcnn/config.py 中,将 __C.USE_GPU_NMS = True 改为 False
将 $FRCN_ROOT/lib/fast_rcnn/nms_wrapper.py 替换成如下代码
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
from fast_rcnn.config import cfg
def nms(dets, thresh, force_cpu=False):
"""Dispatch to either CPU or GPU NMS implementations."""
if dets.shape[0] == 0:
return []
if cfg.USE_GPU_NMS and not force_cpu:
from nms.gpu_nms import gpu_nms
return gpu_nms(dets, thresh, device_id=cfg.GPU_ID)
else:
from nms.cpu_nms import cpu_nms
return cpu_nms(dets, thresh)
这里再加一个小 trick:打开下面几个文件
$FRCN_ROOT/tools/test_net.py
$FRCN_ROOT/tools/train_net.py
找到
caffe.set_mode_gpu()
caffe.set_device(args.gpu_id)
改成
if args.gpu_id>=0 :
caffe.set_mode_gpu()
caffe.set_device(args.gpu_id)
else:
caffe.set_mode_cpu()
打开
$FRCN_ROOT/tools/train_faster_rcnn_alt_opt.py
找到
caffe.set_mode_gpu()
caffe.set_device(cfg.GPU_ID)
改成
if cfg.GPU_ID>=0 :
caffe.set_mode_gpu()
caffe.set_device(cfg.GPU_ID)
else:
caffe.set_mode_cpu()
由于 GPU_ID 是一个必须填写的参数,这样修改的话,我们只要把 GPU_ID 填写成一个负数就可以使用纯 CPU 来跑了,代码更改量比较少。虽然我知道有些地方的规定是「-1 means all」。
Let’s 编译 it !
编译 Caffe 这个坑算是跳出来了。直接按照 这个笔记 来进行编译就好了。 在这里有几点需要注意:
- 必须开启
USE_PYTHON_LAYER = 1,py-faster-rcnn 的有几个层是拿 Python 写的,不开启的话 一定 会出问题。 - Python 请使用 Python2 而不是 Python3 。
- 如果没有升级 Caffe,那么请不要使用 CUDA8.0 。
- 如果使用 GPU,必须使用
USE_CUDNN := 1,否则无论你显存多大,都会报 “显存溢出” 的错误。
除此之外,我们还需要在 $FRCN_ROOT/lib 里面 make 一下。这个是编译上面提到的 NMS 。如果报错,请检查一下 cudaconfig 里面的 lib64:如果是通过 apt 安装的,这个路径可能是 /usr/lib/nvidia-cuda-toolkit,如果是从 NVIDIA 官网上下载的 Cuda8.0,那么路径可能是 /usr/local/cuda 。
跑一下测试 Demo
这个是必须的!用来检验上面的成果。 首先下载训练好的模型
./data/scripts/fetch_faster_rcnn_models.sh
然后
./tools/demo.py
纯 CPU(--cpu)的话,应该不到五分钟就能出来结果了…… 嗯……
跑一下训练 Demo
./experiments/scripts/faster_rcnn_alt_opt.sh -1 VGG16 pascal_voc
本来想验证一下训练有没有什么错误。由于是纯 CPU 在跑,跑了 4 天,才跑了第一阶段的四分之一…… 放弃了。
使用自己的数据集进行训练
这里的「训练」其实是 fine tune 。我们可以在 这篇博客 里面大致了解一下通用的 fine tune 是怎么进行的。 大致是这样的:别人写出了一个模型(比如 ABC DE),并辛辛苦苦训练出来了一个权重文件,我把模型最后几层的名字和参数改掉了(比如 ABC YZ),并且训练的时候加上了别人权重文件。那么,Caffe 在训练的时候,会发现「不对啊,模型里面有 YZ 两个层,但是权重文件里面没有着两层的权重」。这个时候,Caffe 会把 ABC 三层的权重直接加载进来,并随机初始化 YZ 两层,之后只(?)训练 YZ 两层,得到新的模型。 我们要做的就是这个事儿。
rbg 大神给出的 faster-rcnn 是在 Pascal VOC 数据集上训练和测试的,这个数据集有 20 个类别。换到我们自己的数据集上,就是一个 X 类检测问题了。比如,我只想检测人,那么就是一个 1 类检测问题。哦不对,还要记得再加上一个默认的「背景类」。 也就是说,我们需要将模型的输出从 21(20 类 + 背景)改为 2(人 + 背景)。
修改模型文件
这里做的替换有点多,建议直接使用「查找 / 替换」功能来解决。注意,查找的时候请使用「匹配整个单词」模式。 来到 $FRCN_ROOT/models/pascal_voc/VGG16/faster_rcnn_alt_opt,打开所有文件
- 查找
21(原有的 20 类 + 背景),替换为2(人 + 背景) - 查找
84(每个框框都有 4 个坐标,21×4=84),替换成8(2×4=8)
下面是改层的名字,但是很多教程里面都把这个给跳过去了,还能跑得溜溜的。保险起见,还是改名字吧。
来到 $FRCN_ROOT/models/pascal_voc/VGG16/faster_rcnn_alt_opt,打开所有文件
- 查找
cls_score,替换为cls_score_my(也就是将层的名字改掉) - 查找
bbox_pred,替换为bbox_pred_my(也就是将层的名字改掉)
如果只是进行上述修改,我们的代码还不能跑,因为作者在写代码的时候硬编码进了 cls_score 和 bbox_pred 这两个层的名字。我们同样需要在代码中将上述名字替换掉。
来到 $FRCNN_ROOT/lib/fast_rcnn/,打开 train.py 和 test.py
- 查找
cls_score,替换为cls_score_my(和上面的名字必须一样) - 查找
bbox_pred,替换为bbox_pred_my(和上面的名字必须一样)
当然,如果你想使用 faster_rcnn_end2end 或者其他的,和上面做相同的修改就行了。
准备数据
先说一下大神的代码:每个数据集有一个特定的数据读取接口,用来描述如何读 annotation 文件、如何读图片等等。这些接口通过一个 factory 来调用。 好像是什么工厂模式?《设计模式》这本书还没啃…… 有空借来啃一下。但是,为了跑一个数据集,去学工厂模式……??代价有点大。 所以大家都是把某个接口改改,形成一个新的接口,来读数据。比如 这个教程。 但是一个接口实在太大了,我脑子 Buffer 太小,照着各种教程改接口都没有成功,改着改着就乱了。 那么,我们可以使用另一种方法:做一个「假的」数据集。也就是说,把我们的数据集按照 Pascal VOC 或者 coco 的格式重新组织。
Pascal VOC 的数据集可以下载到,里面的 annotation 都是 xml 格式的,和我拿到的数据标注不太一样。用 Python 写一个数据转换脚本就可以了。
我拿到的 ground truth 是这样的:
图片编号:[x1,y1,x2,y2][x1,y1,x2,y2]........
举个例子:
120:[171,68,232,129][392,90,463,171]
150:[403,85,470,159][443,71,490,133][217,75,273,139]
自己写了一个脚本,来将这个 ground truth 转换成 Pascal VOC 样式的 xml 数据格式,并自动生成 train 集、 val 集 test 集和 train_val 集(这个是干啥的?)。就是把一个对象转成 xml 。因为数据标注有错误,可能越界,所以加了一点范围的规定。 assert 用来 debug 。
注意顺序一定是「左上 – 右下」。如果不确定的话也可以加一点代码,把框框在图片中框出来看看效果。
找到 $FRCN_ROOT/lib/datasets/pascal_voc.py,做如下修改:
self._classes,里面改成你自己的类别。(我只有一类,那么就是self._classes = ('__background__','person')。需要特别注意背景类!)self._image_ext文件后缀名
如果使用的是 train_faster_rcnn_alt_opt,在 $FRCN_ROOT/tools/train_faster_rcnn_alt_opt.py 中有一个 max_iters,需要根据数据量进行修改四个阶段的迭代次数。好像设置到「正好能跑完 1 代 / 2 代」就可以了,但是在下面的 train_fast_rcnn 中,我看到了 cfg.TRAIN.IMS_PER_BATCH = 2,所以__感觉__max_iters 中的所有数值都要除以 2 。(对么?求指教)
更正: 第一和第三步的 batch_size=1,第二和第四步的 batch_size=2 。默认是 VOC 数据集跑 16 代。
开始跑!
上面写了这么多,终于可以开始跑了。
./experiments/scripts/faster_rcnn_alt_opt.sh -1 VGG16 pascal_voc
我是拿纯 CPU 跑的,所以里面你可以看到一个 -1 。如果有 GPU 的话,写上 GPU 的 编号 就可以了。训练过程中可以看到 loss 。对于第一阶段(因为数据比较整齐),我还写了一个暴力的 loss 可视化脚本。
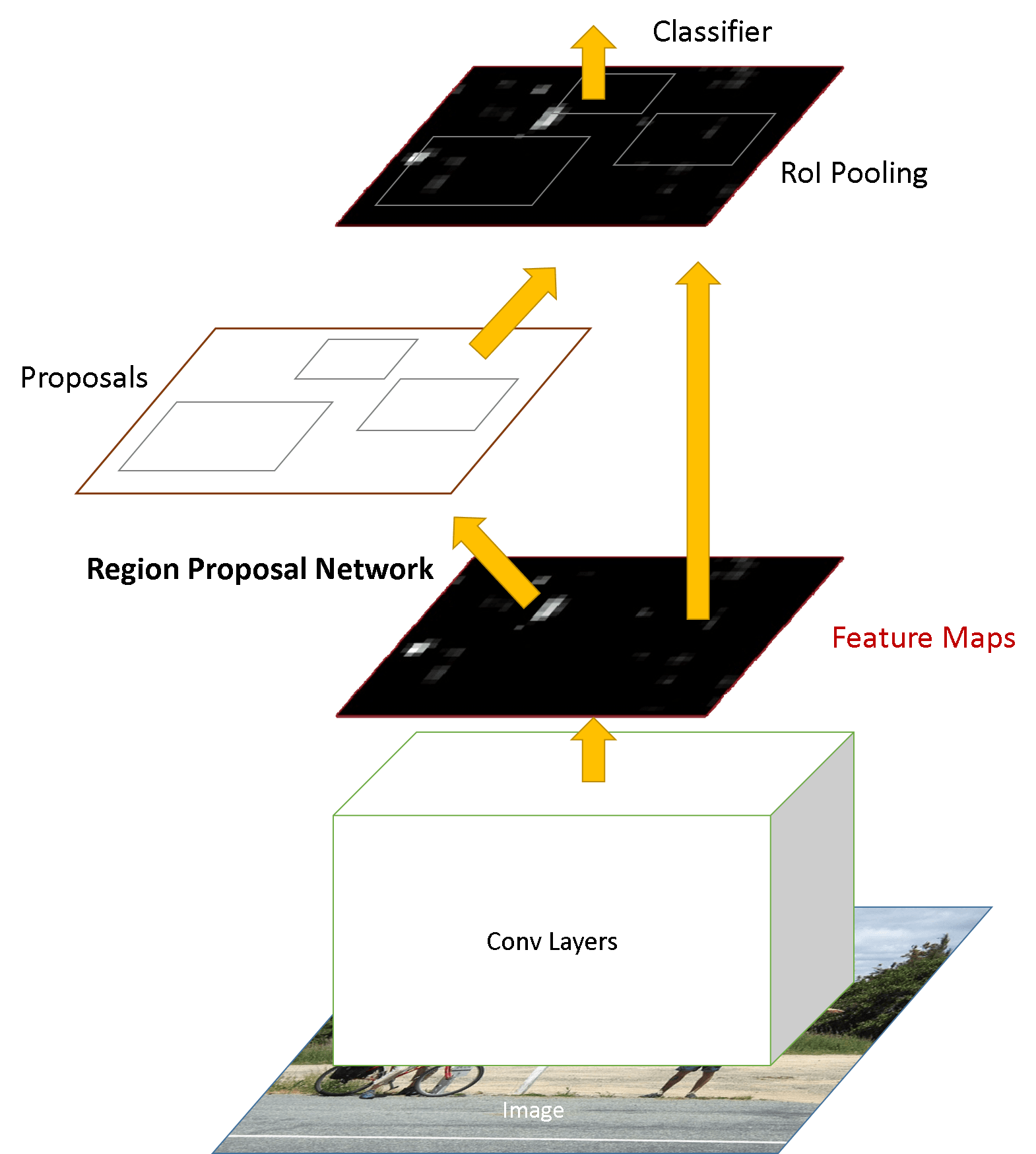 生成的权重文件在
生成的权重文件在 $FRCN_ROOT/output 里。 如果数据标错了,例如不是按照「左上 – 右下」的顺序标的,那么需要删除 $FRCN_ROOT/data/cache 里面的 Cache 。这个 Cache 不知道是干什么用的。
错误处理
- 如果在最后出现
KeyError: 'xxxxxxxxxx',请删除$FRCN_ROOT/data/VOCdevkit2007/annotations_cache/annots.pkl - 如果中途发现标错了数据,重新标注数据后,请删除
$FRCN_ROOT/data/cache/voc_2007_trainval_gt_roidb.pkl - 如果最后测试出现
IndexError: too many indices for array,那是因为你的测试数据中缺少了某些类别。请根据错误提示,找到对应的代码($FRCN_ROOT/lib/datasets/voc_eval.py第 148 行),前面加上一个 if 语句:
if len(BB) != 0:
BB = BB[sorted_ind, :]
写在最后
感谢你能看完。如果你有任何疑问,请在下面评论区留言。博客流量小,所以几乎都会回复的。
参考资料
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- Caffe 安装手记
- CPU 跑 Faster RCNN Demo
- GPU 跑 Faster RCNN Demo
- Support 1080P and cudnn v5?
- Implement CPU layer ops for ROIPoolingLayer and SmoothL1LossLayer
- Training Fast R-CNN on Right Whale Recognition Dataset
- Train Fast-RCNN on Another Dataset
- Train Py-Faster-RCNN on Another Dataset
- Faster-RCNN+ZF 用自己的数据集训练模型 (Python 版本)
- Problem with Proposal Layer
- TypeError: ‘numpy.float64’ object cannot be interpreted as an index