自己的电脑 GPU 太老了,Theano 都给提示说不支持。
那好,下面记录一下如何使用 CPU 来跑 Faster RCNN 。
编译
过程比较坎坷:
- 代码里面带的 Caffe 版本比较老,所以我们需要将它 升级为新版。
-
原始版本里面有两个东西是没有 CPU 实现的。我们需要自己来写或者补这部分的实现。这里有几个版本:第一个版本(推荐,不会出错) / 第二个版本(好像有点问题)
-
在
$/FRCN_ROOT/lib/setup.py中,注释掉CUDA = locate_cuda()、self.set_executable('compiler_so', CUDA['nvcc']),并注释掉ext_modules中的nms.gpu_nms段。 -
将
$FRCN_ROOT/lib/fast_rcnn/config.py中 205 行的__C.USE_GPU_NMS = True改成__C.USE_GPU_NMS = False -
将
$FRCN_ROOT/lib/fast_rcnn/nms_wrapper.py中的第 9 行from nms.gpu_nms import gpu_nms注释掉 -
在
$/FRCN_ROOT/lib中make一下。
这里需要说一下:编译过程中不管用不用 GPU 好像都需要配置 CUDA 。 CUDA8.0 编译不通过,CUDA7.5/8.0 编译 Test 均通不过。不要使用 Python3 。
跑测试 Demo
首先去下载训练好的模型:
cd $FRCN_ROOT
./data/scripts/fetch_faster_rcnn_models.sh
之后是直接调用模型进行训练:
./tools/demo.py --cpu
应该可以看到效果。
跑训练 Demo
前面都是在 “跑测试” 。如果 “跑训练” 的话,修改的代码会更多(因为人家压根没想让你用 CPU 训练):
在 $/FRCN_ROOT/tool/train_faster_rcnn_alt_opt.py 和 $/FRCN_ROOT/tool/test_net.py 中注释掉 caffe.set_mode_gpu() 和 caffe.set_device(cfg.GPU_ID),并替换为 caffe.set_mode_cpu(),或者用其他相似的办法(比如,GPU_ID 小于 0 那么就用 CPU)。
在 $/FRCN_ROOT/lib/fast-rcnn/train.py 中,加入 import google.protobuf.text_format 。
然后,按照官方 Readme 获取所有训练数据和进行 Train 了。
./experiments/scripts/faster_rcnn_alt_opt.sh 0 VGG16 pascal_voc
speed: 4.715s / iter
I0108 10:48:46.286895 12158 solver.cpp:229] Iteration 800, loss = -nan
I0108 10:48:46.286941 12158 solver.cpp:245] Train net output #0: rpn_cls_loss = -nan (* 1 = -nan loss)
I0108 10:48:46.286953 12158 solver.cpp:245] Train net output #1: rpn_loss_bbox = -nan (* 1 = -nan loss)
I0108 10:48:46.286959 12158 sgd_solver.cpp:106] Iteration 800, lr = 0.001
I0108 10:50:19.026899 12158 solver.cpp:229] Iteration 820, loss = -nan
I0108 10:50:19.026938 12158 solver.cpp:245] Train net output #0: rpn_cls_loss = -nan (* 1 = -nan loss)
I0108 10:50:19.026952 12158 solver.cpp:245] Train net output #1: rpn_loss_bbox = -nan (* 1 = -nan loss)
I0108 10:50:19.026957 12158 sgd_solver.cpp:106] Iteration 820, lr = 0.001
I0108 10:51:54.533910 12158 solver.cpp:229] Iteration 840, loss = -nan
I0108 10:51:54.533948 12158 solver.cpp:245] Train net output #0: rpn_cls_loss = -nan (* 1 = -nan loss)
I0108 10:51:54.533954 12158 solver.cpp:245] Train net output #1: rpn_loss_bbox = -nan (* 1 = -nan loss)
I0108 10:51:54.533960 12158 sgd_solver.cpp:106] Iteration 840, lr = 0.001
I0108 10:53:27.829391 12158 solver.cpp:229] Iteration 860, loss = -nan
I0108 10:53:27.829433 12158 solver.cpp:245] Train net output #0: rpn_cls_loss = -nan (* 1 = -nan loss)
I0108 10:53:27.829447 12158 solver.cpp:245] Train net output #1: rpn_loss_bbox = -nan (* 1 = -nan loss)
loss 是负无穷,说明根本没收敛啊。但是,你不觉得,作为官方 Demo,应该任何地方都不用动就能达到文档中的效果才对么?
也查了一些资料。今天早上突然眼尖发现了几个有用的。
首先是 这里,说道 “如果出现 NaN,需要降低学习率”,但是有人反应说,把学习率降到 0 仍然出现 NaN 。
然后是 这里,这个博主也是拿 CPU 训练的。把 /home/wjx/py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt 文件夹下将四个 solver 文件里面的 base_lr 由 0.001 调小一点。
最后是 这里。由于博文比较短,就直接搬运过来:
caffe 在 cifar10 的 example 上给出了两个模型,一个是 quick 模式,一个是 full 模式,训练 full 模式时会出现 loss=nan 的错误(当然不会报错,不过出现这个结果就是 bug)
自己 google 了一下,在 github 上找到了原因跟解决方案,原来是作者把用在 cuda-convnet 的模型照搬过来了,在 caffe 上的模型应该去掉 LRN 层,所以解决的方法很简单:将网络结构中所有的归一化层全部去掉,并修改下一层的 bottom 参数,然后就不会出现 loss=nan 的错误了。
当然,如果自己做实验时出现 loss=nan 的问题时,我的一个解决办法是修改学习率,改的小一点就不会出现错误了。实在不行,就把里面的 relu 函数变为 sigmoid 试一试,代价就是训练速度会非常非常慢。
还有一个要检查的点就是要看一下网络的结构是否合理,我在网上下载的 network in network 的网络结构,最后一层竟然没有一层全连接把输出变为类别数,这让训练陷入了要么出现 nan 要么结果一直不变的 bug 境地。
自己尝试了将 base_lr 从 0.001 降到了 0.0001,效果不明显。原来是 20 轮出现 NaN,现在是 40 轮出现 NaN 。按照这个形式发展下去,是不是得把学习率降到 1e-1000000 左右才能完整跑完训练?
然后又试着把 base_le 降到 0.00001(1e-5),好像正常了。目前跑了 100 多轮,没有 NaN 。
一个监视脚本
由于没有装可视化的东西,只能自己进行可视化的工作。好在输出的 Log 里面有足够的信息。
下面是可视化的效果: 横坐标是迭代的轮数,纵坐标是 Loss 。
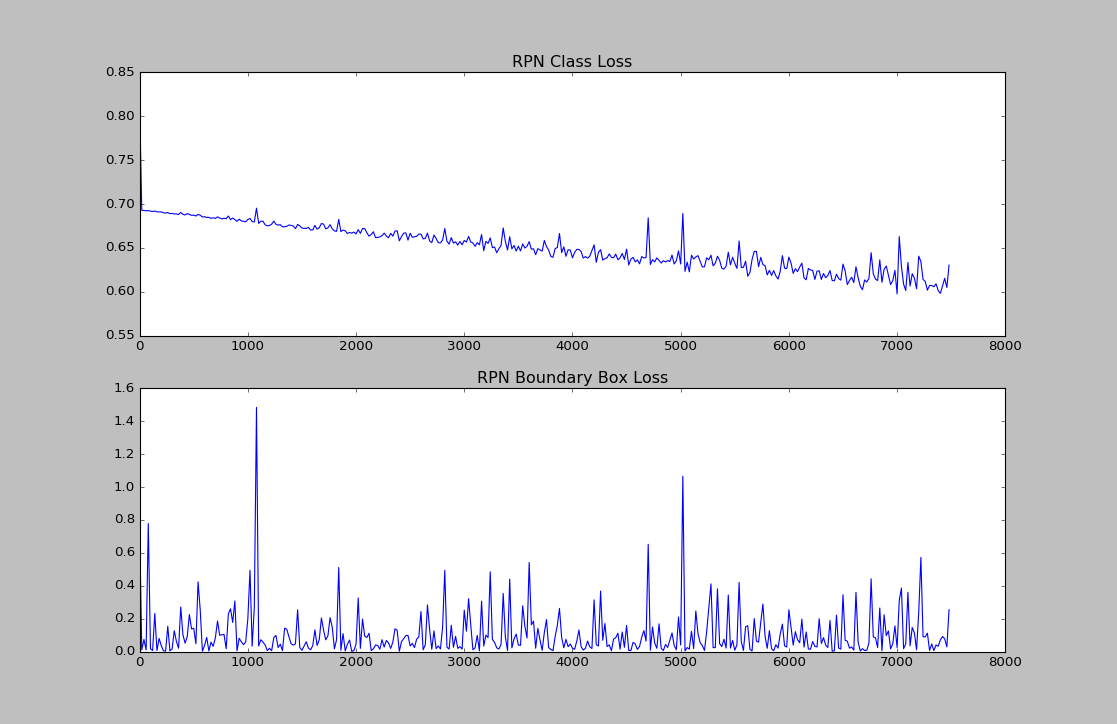
对应的代码(很暴力):
# -*- coding: utf-8 -*-
import re
import numpy as np
import matplotlib.pyplot as plt
def str2num(str_list, output_type):
return [output_type(x) for x in str_list]
if "__main__" == __name__:
log_file = "/home/haoyu/Workspace/PycharmProjects/py-faster-rcnn/experiments/logs/faster_rcnn_alt_opt_ZF_.txt.2017-01-09_09-35-32"
pattern_itr = re.compile(r"106\]\s+Iteration\s+([\d]+)")
pattern_rpn = re.compile(r"rpn_cls_loss[\s=]{1,3}([\d\.]+)")
pattern_box = re.compile(r"rpn_loss_bbox[\s=]{1,3}([\d\.]+)")
with open(log_file, 'r') as f:
lines = f.read()
itrs = pattern_itr.findall(lines)
rpns = pattern_rpn.findall(lines)
boxs = pattern_box.findall(lines)
itrs = np.array(str2num(itrs, int))
rpns = np.array(str2num(rpns, float))
boxs = np.array(str2num(boxs, float))
plt.figure()
plt.sca(plt.subplot(211))
plt.plot(itrs, rpns)
plt.title("RPN Class Loss")
plt.sca(plt.subplot(212))
plt.plot(itrs, boxs)
plt.title("RPN Boundary Box Loss")
plt.show()
后记
Caffe 版本太多了…… 官方版。 nlp caffe,这里还有个 caffe-rcnn …… 个人魔改的版本都是 “改了之后就弃坑”,每个版本的错误都不一样……
心累
更心累的是,没有 GPU……
另:求解释为什么 bbox 的 loss 一直是震荡的?
更新: 使用 GPU 跑 Demo 的失败例子在这里,倒不是因为方法失败了,而是因为显卡不给力。不过这个文章里面记录了如何升级 caffe 、如何解决 make test 失败的方法。